From LoRaWAN Pilot to Production: Why 70% of IoT Projects Never Scale
The Pilot Worked. Now What?
The proof of concept was a success. Ten sensors deployed in one building. Data flowing into dashboards. Stakeholders impressed. Budget approved for the full rollout: 500 devices across twelve sites.
Six months later, the project is stalled. The gateway that worked fine for ten sensors can't handle the traffic. The vendor who sold you the pilot hardware doesn't offer volume pricing. The IT department won't approve the network architecture you prototyped on a Raspberry Pi. The facilities team at site #4 refuses to grant roof access for antennas.
This is pilot purgatory. And according to industry data, roughly 70% of enterprise IoT projects never escape it.
The root cause is almost never the technology. LoRaWAN works. The sensors measure. The gateways forward. The network server processes. What breaks is everything around the technology—procurement, IT policy, operational processes, organizational alignment, and architecture decisions that worked at 10 devices but collapse at 500.

A successful pilot proves the technology works. It proves nothing about whether your organization can deploy, operate, and maintain the system at scale. These are entirely different problems.
Why Pilots Succeed and Rollouts Fail
The Pilot Was Too Easy
Most pilots are designed to succeed. Single site. Cooperative facilities manager. Favorable RF environment. Sensors placed within line of sight of the gateway. IT security waved through as a "temporary test." Manual data export into spreadsheets because the dashboard integration wasn't built yet.
None of this translates to production. Production means hostile RF environments, multiple buildings with different construction materials, IT security reviews that take months, facilities teams who never heard of LoRaWAN, and automated data pipelines that must work without manual intervention.
The fix: Design pilots that expose production challenges deliberately. Include at least one difficult site—thick concrete, basement, or long range. Involve IT security from day one. Require automated data flow, not manual export. If your pilot doesn't surface problems, it isn't testing anything useful.
Architecture That Doesn't Scale
The most common technical failure: pilot architecture that becomes a liability at scale.
Network server on a Raspberry Pi. Fine for 10 devices. A production system handling 500+ devices across multiple sites needs redundancy, backup, monitoring, and performance that a single-board computer cannot provide. ChirpStack on a properly sized Linux server—2-4 CPU cores, 8 GB RAM, SSD storage—handles thousands of devices reliably. The migration from Pi to production server is straightforward, but only if planned from the start.
Single gateway, single point of failure. Pilots run one gateway. Production needs redundancy. When that gateway goes offline at 2 AM—power outage, Ethernet failure, hardware fault—every sensor behind it goes dark. Production deployments use overlapping gateway coverage so that no single failure creates a monitoring gap. Budget for N+1 gateways, not minimum coverage.
Flat network design. Ten devices on one application in one tenant on the network server. Five hundred devices need multi-tenant separation, role-based access, device grouping by site and function, and clear ownership boundaries. ChirpStack supports this natively, but the organizational structure needs defining before devices multiply.
No firmware update path. Pilot devices get configured once and left alone. Production devices need firmware updates—bug fixes, security patches, protocol changes. If you selected hardware without FUOTA (Firmware Update Over The Air) support or didn't test the update mechanism during the pilot, you're facing physical site visits to 500 devices when the first critical bug appears.
Procurement Hits Reality
Pilot hardware comes from a distributor's shelf. Ten sensors, two gateways, a credit card purchase. The full rollout triggers enterprise procurement, and everything changes.
Volume pricing isn't automatic. That €80 sensor might drop to €55 at 500 units—or it might not. Some manufacturers have aggressive volume discounts. Others barely move. Negotiate before committing to a hardware platform. Get formal quotes for your target volumes. The difference between €80 and €55 per sensor across 500 units is €12,500.
Lead times. Small orders ship in days. Large orders ship in weeks or months. Sensor manufacturers, particularly during component shortages, quote 8-16 week lead times for volume orders. Plan your deployment timeline around actual hardware availability, not the next-day delivery you experienced during the pilot.
Hardware certification. Enterprise IT and compliance teams want to know: Is this device CE marked? Does it meet your organization's cybersecurity requirements? Is the manufacturer's supply chain reliable? Who provides warranty support? Questions nobody asked about the pilot hardware become procurement blockers at scale.
Standardization. The pilot used whatever was available. Production needs standardized hardware across all sites—same sensor models, same gateway models, same firmware versions. Mixing hardware creates a maintenance nightmare: different battery types, different mounting systems, different payload formats, different decoder configurations.
IT and Security Block Everything
The pilot ran under the radar. The rollout needs IT approval.
Network segmentation. LoRaWAN gateways connect to your network via Ethernet or cellular backhaul. IT security wants them on a dedicated VLAN, behind a firewall, with traffic restricted to the network server. The Raspberry Pi plugged into a desk port during the pilot? Not acceptable.
Server infrastructure. Self-hosted ChirpStack needs a VM in the data center or an approved cloud environment. IT needs to know: who maintains it, who patches it, what's the backup strategy, what's the disaster recovery plan, where does the data reside, who has access? These are legitimate questions that take time to answer properly.
Data classification. What data are the sensors collecting? Temperature in a server room might be classified as operational data. Occupancy patterns in an office building might be personally identifiable information under GDPR. Water consumption in a hospital has different sensitivity than humidity in a warehouse. Data classification determines storage requirements, access controls, and retention policies.
The fix: Involve IT security during the pilot, not after. Write the security architecture document before requesting production approval. Address network segmentation, data classification, access control, and maintenance responsibilities upfront. The six months you lose to IT review after a successful pilot is six months you could have spent running in parallel.
The EPBD Driver: Regulatory Pressure to Scale Now
For organizations operating commercial buildings in the EU, the window for gradual IoT adoption is closing.
The revised Energy Performance of Buildings Directive (EPBD, EU/2024/1275) requires EU member states to transpose into national law by 29 May 2026. Article 14 mandates Building Automation and Control Systems (BACS) in all non-residential buildings where heating, ventilation, or air conditioning systems exceed 290 kW effective rated output. By 2030, that threshold drops to 70 kW—pulling the majority of commercial buildings into scope.
Compliant BACS must continuously monitor and log energy use, benchmark efficiency, detect system losses, and allow communication with connected building systems. From May 2026, indoor environmental quality monitoring is also required. This means temperature sensors, CO2 sensors, humidity sensors, occupancy detection—exactly the LoRaWAN sensor categories that sit in pilot purgatory at many facility management organizations.
The penalty for non-compliance isn't a suggestion. Member states set enforcement mechanisms, but building energy performance certificates, renovation requirements, and potential fines create real consequences. Organizations that have a successful LoRaWAN pilot monitoring one building but haven't scaled to their full portfolio face a regulatory deadline that doesn't care about procurement delays or IT approval processes.
The fix: Use the EPBD mandate as the forcing function to break through organizational inertia. Regulatory compliance gets budget, IT prioritization, and executive attention that "energy efficiency improvement" alone rarely achieves. Frame your scaling plan as compliance, not optimization.
Operational Gaps That Kill at Scale
No Device Lifecycle Management
Ten pilot devices fit in a spreadsheet. Five hundred devices need a proper asset management system.
Every device has a lifecycle: procurement, provisioning, deployment, operation, maintenance, battery replacement, firmware update, decommissioning. At pilot scale, one person tracks this in their head. At production scale, you need documented processes and tooling.
Device provisioning at scale means batch registration in the network server, pre-configured device profiles, standardized naming conventions, and automated OTAA (Over-The-Air Activation) key management. Manual AppKey entry for 500 devices is a full week of error-prone work that should be scripted.
Battery management means knowing which devices need replacement and when. A system with 500 sensors on 5-year batteries starts requiring 100 replacements per year from year 3. Without tracking battery installation dates and monitoring device voltage levels, you discover dead sensors when users notice missing data.
Replacement strategy means keeping spare inventory. Budget for 5-10% spare sensors and at least one spare gateway per site. Overnight shipping a replacement gateway from a European distributor takes 2-3 days. Explain to stakeholders why monitoring went dark for 72 hours because nobody stocked a spare.
No Monitoring of the Monitoring System
The sensors monitor your building. What monitors your sensors?
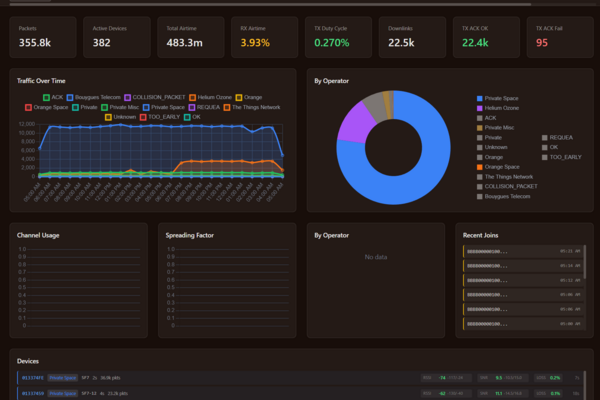
At pilot scale, you check the dashboard daily and notice when data stops. At production scale with 500 devices across twelve sites, you cannot visually inspect every data stream. You need automated monitoring: alerts for devices that stop reporting, gateways that go offline, data that falls outside expected ranges, and battery levels approaching replacement thresholds.
Grafana handles this well with alerting rules—but those rules need designing, testing, and maintaining. An alert that fires every time a sensor misses a single uplink at 3 AM generates noise that gets ignored. An alert that waits for three consecutive missed uplinks before escalating catches real problems without alert fatigue.
Uplink monitoring: Define expected reporting intervals per device type. Temperature sensors reporting every 15 minutes should trigger investigation after 3 missed uplinks (45 minutes). GPS trackers reporting hourly should alert after 3 hours. Adjust thresholds to the device behavior, not a universal timeout.
Gateway monitoring: Gateway heartbeat monitoring is critical. A gateway outage affects every device behind it. Alert immediately when a gateway stops reporting to the network server. Automate a check for gateway last-seen timestamps.
Data quality: Sensors can report while sending garbage. A temperature sensor stuck at -40°C is reporting—but the data is meaningless. Range checks and rate-of-change validation catch sensor failures that simple uplink monitoring misses.
Documentation Nobody Writes During the Pilot
The pilot engineer keeps the architecture in their head. Device placement, network configuration, decoder settings, dashboard queries, alert thresholds—all tribal knowledge.
That engineer goes on holiday. Or leaves the company. Or simply forgets which sensor model uses which decoder template six months later.
Production deployments require documentation:
- Network architecture diagram: Gateways, backhaul connections, server topology, data flow
- Device inventory: Every device with its DevEUI, location, installation date, battery installation date, sensor type, mounting details
- Decoder library: Payload decoders for every device type, version-controlled and tested
- Dashboard templates: Standardized Grafana dashboards per use case, documented variables and queries
- Runbook: What to do when a gateway goes offline, when a sensor stops reporting, when a battery alert fires, when the server needs maintenance
Write documentation during deployment, not after. It takes 10% more time during installation and saves weeks of confusion later.
The Scaling Playbook
Phase 1: Harden the Pilot (Month 1-2)
Before adding a single device, make the pilot production-ready:
- Migrate to production infrastructure. Network server on a proper VM with automated backups. No Raspberry Pi. No desktop port Ethernet.
- Implement monitoring. Automated alerts for device health, gateway status, and data quality. Test the alert pipeline end-to-end—send a test alert to whoever carries the on-call phone.
- Document everything. Network architecture, device inventory, decoder configurations, dashboard templates, maintenance procedures.
- Security review. Get IT approval for the network architecture. Address segmentation, access control, data classification, and maintenance responsibilities.
- Standardize hardware. Confirm volume pricing and lead times for the sensor and gateway models you'll deploy at scale.
Phase 2: Prove the Process (Month 3-4)
Deploy one additional site using production processes:
- Site survey. RF coverage assessment, gateway placement, sensor locations, power and network availability. Document the process so site #3 follows the same procedure.
- Standardized deployment. Use the documented provisioning process, decoder templates, and dashboard configurations. If anything requires manual workarounds, fix the process before proceeding.
- Handover. Train local facilities staff on basic operations—what the sensors do, what the alerts mean, who to call when something needs attention.
- Validate operations. Run for 30 days monitoring system health, data quality, and operational processes. Fix issues before scaling further.
Phase 3: Scale (Month 5+)
With proven infrastructure, documented processes, and validated operations, deploy remaining sites in parallel batches:
- Batch deployment. 2-4 sites per batch, depending on team capacity. Each batch follows the standardized process from Phase 2.
- Continuous improvement. Each batch reveals new edge cases—unusual building construction, unexpected RF interference, facilities teams with different access procedures. Feed lessons back into documentation.
- Capacity monitoring. Watch network server performance, database growth, and gateway channel utilization as device counts increase. Scale infrastructure proactively, not reactively.
What I Provide
Scaling LoRaWAN from pilot to production is an integration and architecture challenge—bridging technology, IT policy, procurement, and operations into a system that works reliably at scale. This is consulting work by nature: you need the expertise to design and deploy the system, then the knowledge transfer to operate it independently.
Services:
- Production architecture design: network topology, redundancy, security, and scalability review
- Pilot assessment: identifying what needs hardening before scaling
- Multi-site deployment planning: site surveys, hardware standardization, procurement strategy
- Network server migration: from prototype to production-grade ChirpStack infrastructure
- Device lifecycle tooling: provisioning automation, monitoring, battery tracking
- Grafana alerting and operational dashboards for fleet management
- IT security documentation: network architecture, data flow, access control, GDPR compliance
- EPBD/BACS compliance strategy: sensor selection and deployment for regulatory requirements
- Team training: operations, maintenance procedures, troubleshooting
You own everything:
- Complete infrastructure: network server, database, dashboards, alerting
- All source code for decoders, integrations, and automation scripts
- Documentation: architecture, inventory, runbooks, deployment procedures
- No recurring platform fees, no vendor dependency
Hardware (you source):
- Production-grade gateways with redundancy
- Standardized sensors across all sites
- Server infrastructure (on-premise or approved cloud)
- Spare inventory for maintenance
I don't sell hardware or charge recurring fees. I help organizations that have proven LoRaWAN works in a pilot get it running reliably across their entire operation. The technology isn't the hard part—scaling it is.
Ready to Get Started?
Get expert guidance on implementing LoRaWAN solutions for your organization.
Let's Talk